TL;DR
- Benchmark: I tested top LLMs with image support (Feb 2026) on a UI element detection task to help acquire labels for a side project.
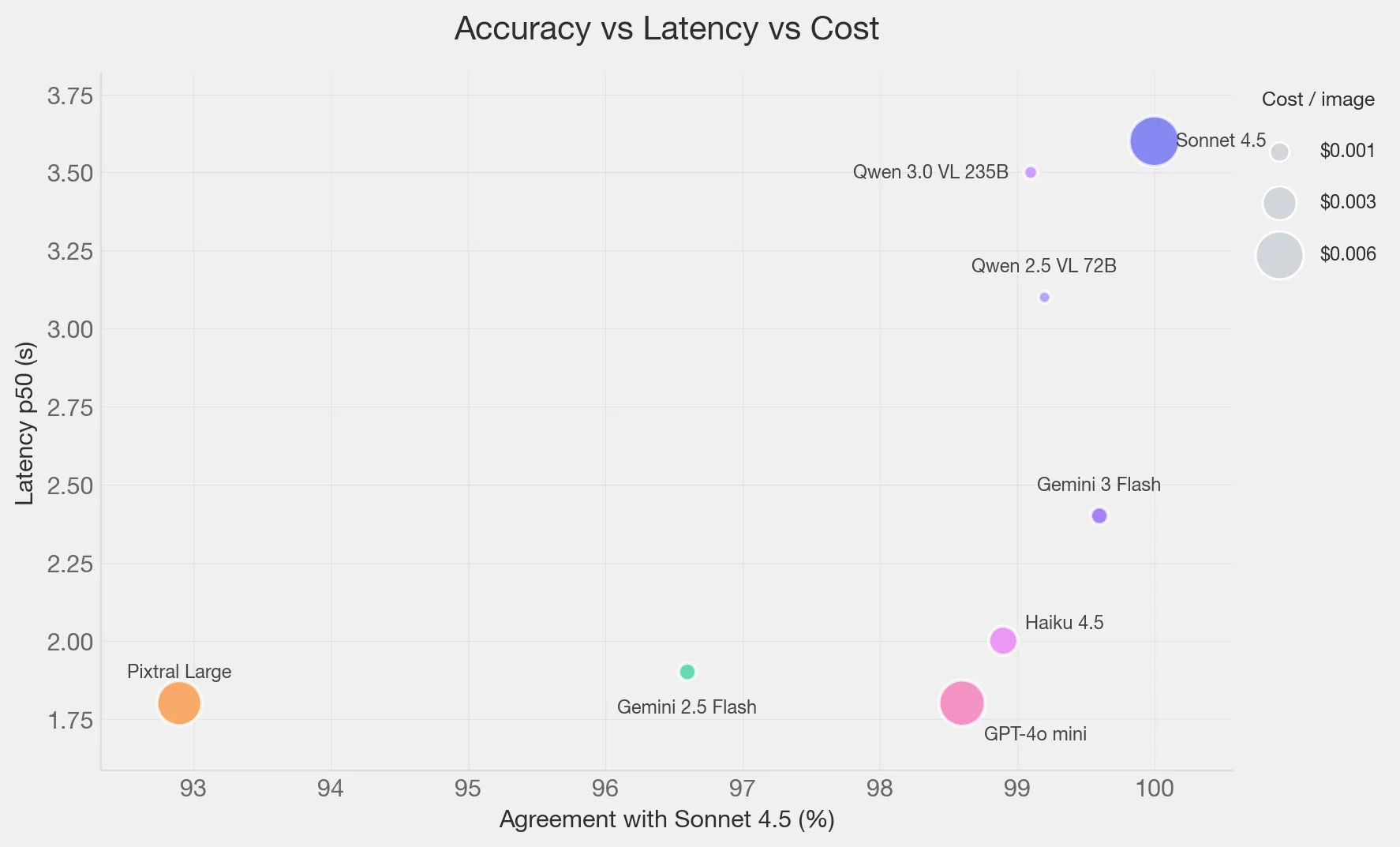
- Top Choices: Using Sonnet 4.5 as anchor, Gemini 3 Flash is a great choice, with good latency and better cost.
- Runner Up: Qwen 3.0 VL 235B was a very close second. It’s cheaper than Gemini, but a bit slower, and more limited for non-english content.
Why?
I have a side project, where I’m trying to detect cookie consent windows in realtime with a browser extension. For that I wanted labels for cases where the cookie consent window was in view, but the detector missed it. There is some context awareness needed, lots of banner and placement types, so this felt like a good task for a vision LLM.
Some interesting situations arise when the consent window looks like a simple overlay but is actually in an iFrame. This setup makes it tricky to locate with DOM inspection alone when the iFrame is cross-origin.
I was using Sonnet 4.5, which after reviewing many examples seemed very capable for this. It was a bit expensive & slow for the task at hand, assuming larger scale to come. To streamline I downgraded to Haiku, but immediately saw mis-classification errors. What followed was a quick benchmarking exercise.
The Setup
The data
Started with a small run (~1k) of screenshots of the viewport of website landing pages. I had saved these in jpg and they were all 1920 x 993 px (1920x1080 window minus the Chromium UI elements).
Files sizes were in the hundred KB range, with p50 ~150KB and p90 ~240KB, and nothing over 0.5MB.
The task
I fed each image to different LLMs, with same prompt and all through OpenRouter:
Look at this screenshot of a website. Determine whether a cookie consent dialog, \
cookie banner, or privacy consent notice is visible on the page.
A consent dialog typically:
- Mentions cookies, privacy, GDPR, data protection, or tracking
- Has buttons like "Accept", "Reject", "Manage preferences", "Allow", "Decline", or "OK"
- Appears as a banner (top or bottom), modal/popup overlay, or floating panel
- May be partially transparent or overlay the main page content
Do NOT count:
- Login/signup forms
- Newsletter subscription popups
- Age verification gates
- Generic notification bars unrelated to cookies/privacy
- Cookie preference pages that are the main page content (not an overlay)
Respond with ONLY a JSON object (no markdown fences, no extra text):
{"has_consent_dialog": true/false, "dialog_type": "banner"|"modal"|"popup"|"none", "confidence": "high"|"medium"|"low", "description": "Brief description of what you see"}The LLMs
I reviewed benchmarks like Arena.ai, ArtificialAnalysis.ai and OpenRouter usage. Ended up with a mix covering:
- Closed Weight: Sonnet 4.5, Haiku 4.5, Gemini 2.5 Flash, Gemini 3 Flash, OpenAI 4o mini
- Open Weights: Qwen 3.0 VL 235B, Qwen 2.5 VL 72B, Llama 3.2 11B Vision, Nova Lite v1, Pixtral Large
I stayed clear of reasoning models due to token use and task simplicity.
The Initial Test (1k)
Success rates
Most models did fine with 2 exceptions:
- Nova Lite had ~7% failure rate due malformed json (trailing characters mostly).
- Llama 3.2 11B had ~65% failures, with over half due to Llama Guard safety filter triggering. The balance was also due to malformed json.
I decided to exclude these from the rest of the analysis.
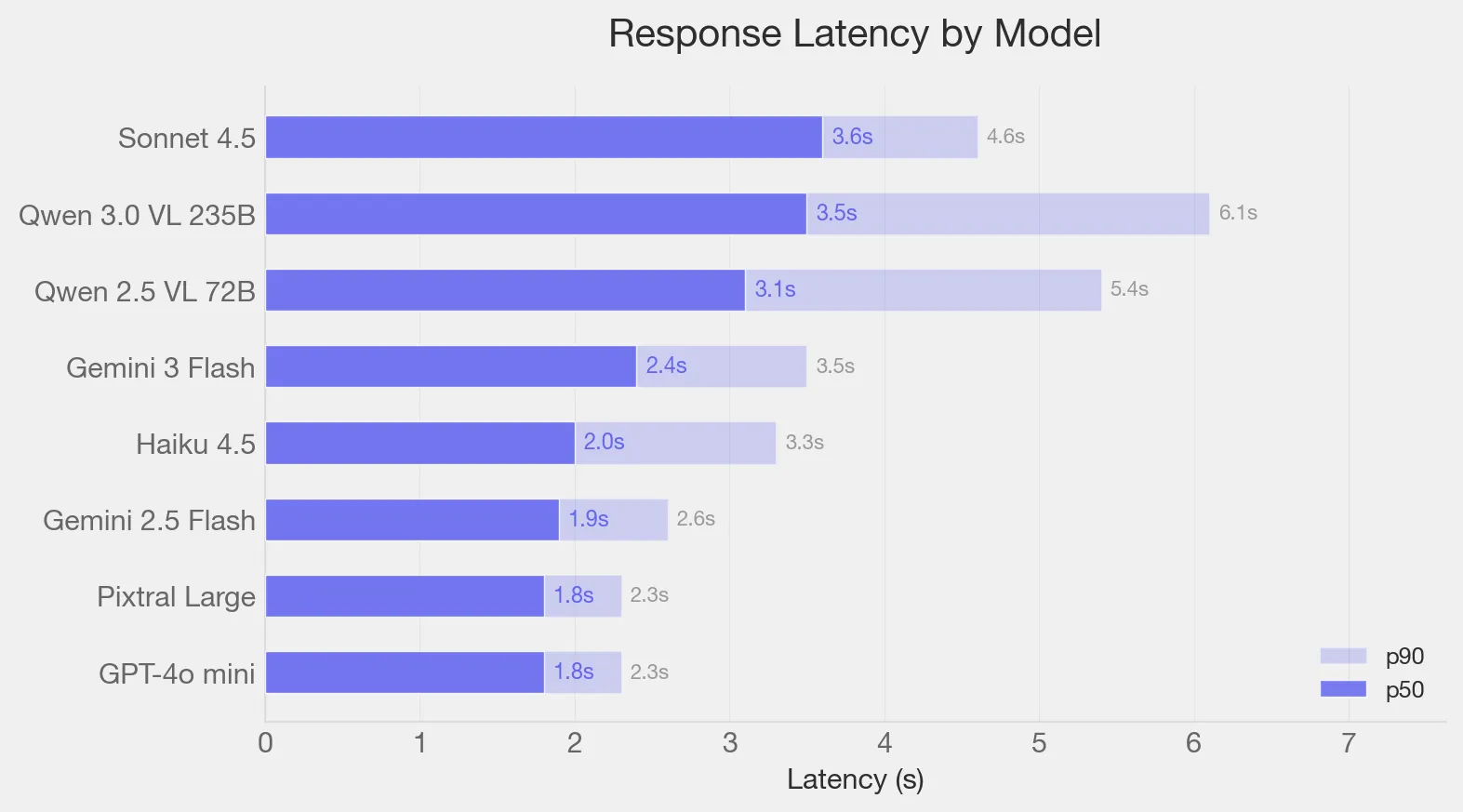
Latency
The latency here reflects partly on OpenRouter so would not index on it too much. Still it gives a directional read on this lightweight task.
Did not expect Pixtral Large to be fast given it’s 124B weights. Turns out this is not a output token heavy task so in this case the weight headline did not matter as much for latency.
Cost
Cost projections were inline with expectations, with GPT-4o mini as the wild card. Reading up, it seems it’s known that it’s heavy on the input side for some images.
Haiku gives a big drop in cost, Gemini is even cheaper and Qwen is another halving.
| Model | Total Input Tokens | Total Output Tokens | Cost / Img |
|---|---|---|---|
| Nova Lite | 2,112,368 | 62,905 | 0.02¢ |
| Llama 3.2 11B | 2,147,148 | 14,475 | 0.03¢ |
| Qwen 2.5 VL 72B | 2,420,112 | 48,900 | 0.04¢ |
| Qwen 3.0 VL 235B | 1,872,786 | 68,533 | 0.05¢ |
| Gemini 2.5 Flash | 1,827,344 | 57,058 | 0.08¢ |
| Gemini 3 Flash | 1,213,334 | 50,555 | 0.08¢ |
| Haiku 4.5 | 1,629,662 | 81,698 | 0.22¢ |
| Pixtral Large | 2,256,666 | 52,759 | 0.53¢ |
| GPT-4o mini | 33,868,270 | 41,048 | 0.56¢ |
| Sonnet 4.5 | 1,627,879 | 85,265 | 0.67¢ |
Based on OpenRouter pricing from Feb 2026.
Agreement across models
Now the interesting part. Assuming Sonnet 4.5 is the anchor, the only 2 that get very close are Gemini 3 Flash and the Qwen models. Haiku gets an honorable 3rd place. Now I knew Haiku had gaps from earlier testing so I focused on the other 2.
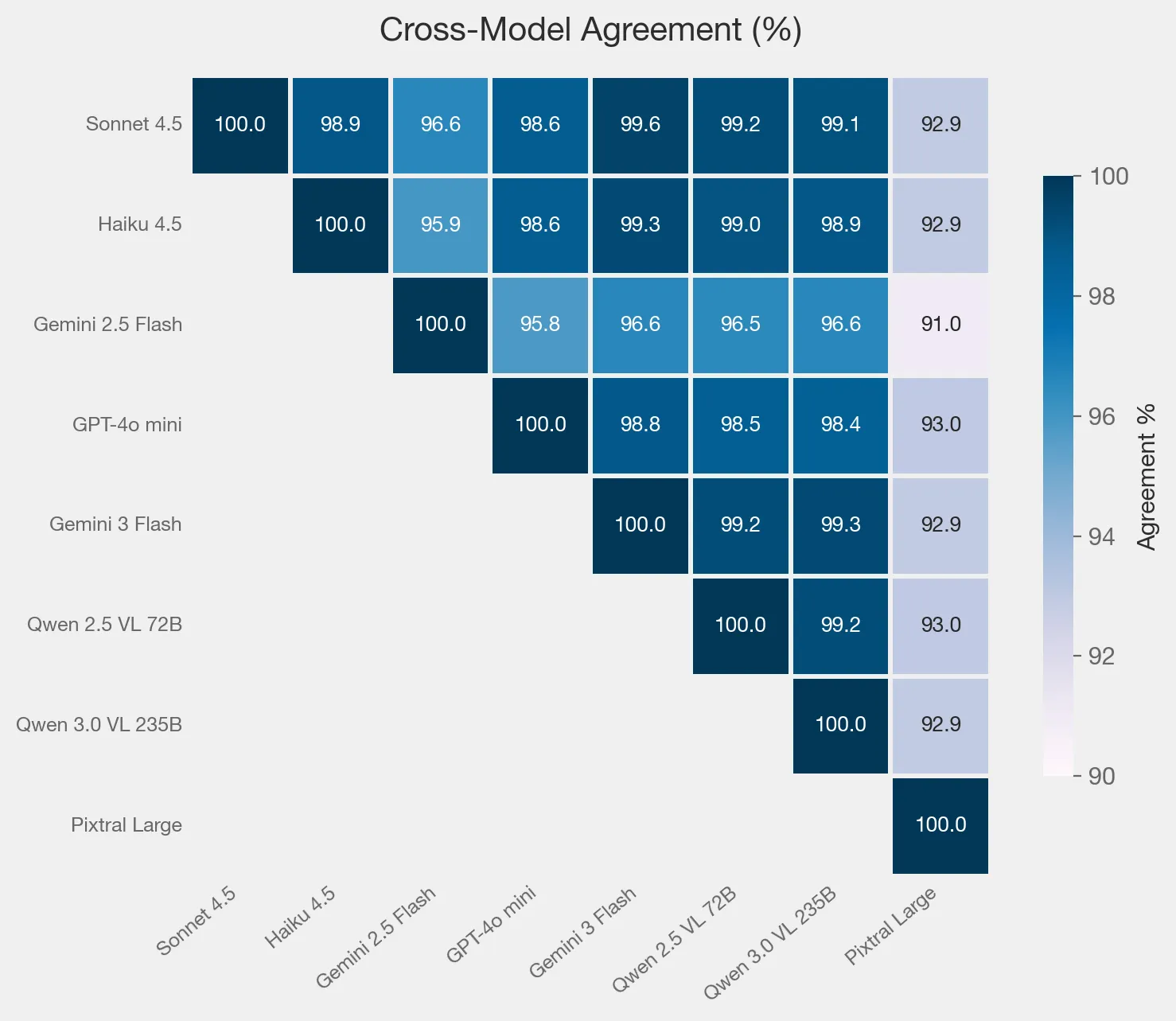
Sonnet 4.5 vs Gemini 3 Flash vs Qwen 3.0
When they all disagreed, I reviewed the images and these were edge cases. Usually it was some modal with terms to review, or basic notices that needed user input, and the term cookie was somewhere else or around the modal.
Focusing on Gemini 3 Flash vs Qwen 3.0 VL 235B and reviewing the examples, they were split 50/50 on a handful disagreements. This led to a larger test.
The Final check (10k)
Results
After a 10k job finished, I ran it through both Gemini 3 Flash vs Qwen 3.0 VL 235B. The agreement between them held up at 99.4%. On the where they disagreed:
- Gemini did a better job at non-english sites, but struggled with age gates that mentioned cookies.
- Qwen triggered less on smaller modals that were not consent related. It also usually missed banners that were not in english.
Confidence level?
The json has a confidence_level and there was no correlation between that and the errors. As a final tweak, I refined the prompt and restructed the confidence output on a 0 to 100 scale. Still it was not useful, and the models kept giving 95+ of the outcomes even when wrong.
Were the labels useful?
The refined prompt improved Gemini, reducing another quarter of the disagreements.
When Gemini disagreed with the in-browser detector it was correct most of the time, as these were iFrame type situations or other edge cases that the detector did not handle well. That was the whole point of doing this, so overall pretty good and enough to keep going.
Conclusion
Either Gemini or Qwen can work. For this use case Gemini Flash 3 has the slight edge with the better language support.
2/16/26 Update - Qwen 3.5
Qwen 3.5 (qwen3.5-397b-a17b) became available, so I tested it out to see if it overcame the Qwen 3.0 limitations.
In short:
- 85% of edge cases were resolved, with non-english handling mostly fixed.
- Cost / Latency took a bit hit, being about 5X more expensive that Gemini 3 Flash and about 8X slower.